CNNs use a mathematical operation called convolution in place of general matrix multiplication in at least one of their layers.
Why CNN?
- curse of dimensionality
- for a single 32x32 pixel image, it will have 3 channel of 1024 pixels. Fully Connected Neural Networks (FCNNs) treat every pixel as an independent input and do not consider the spatial relationship between them. FCNNs require a large number of parameters, making them computationally expensive and prone to overfitting.
- spatial relationship
- CNN can exploit the spatial correlation between pixels in an image. By using convolutional filters, the network can learn to detect patterns regardless of their location within the image.
Convolution Layer
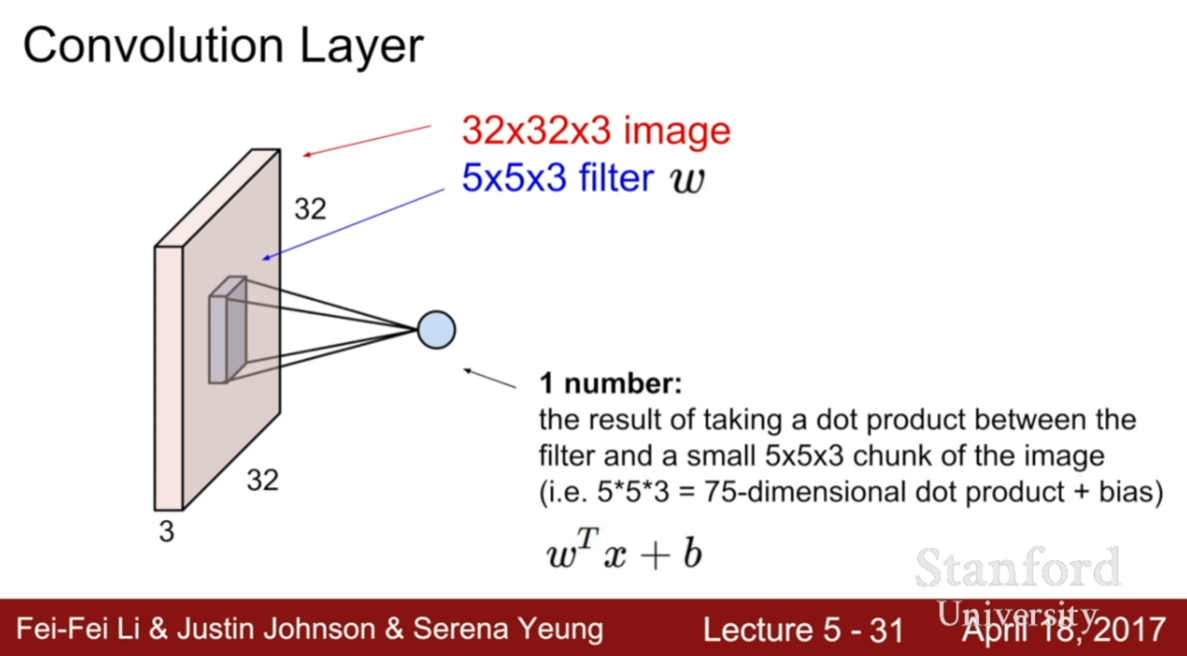 Image is SS from: https://youtu.be/bNb2fEVKeEo
Image is SS from: https://youtu.be/bNb2fEVKeEo
Notice that the number of parameter will always fixed to the size of the filter no matter the input size
Parameter
Accept a volume size of $W_1 \times H_1 \times D_1$ Requires four hyperparameters:
- Number of filters $K$
- size of the filter $F$
- stride $S$
- amount of zero padding $P$
Output: volume size: $W_2 \times H_2 \times D_2$ with:
- $W_2 = (W_1 - F + 2P)/S + 1$
- $H_2 = (H_1 - F + 2P)/S + 1$
- $D_2 = K$