Improving Label Consistency
To enhance the consistency of labels in a project, follow these steps:
-
Multiple Labelers: If label consistency is a concern, select a few examples and have multiple labelers assign labels to them. This approach helps identify inconsistencies among labelers.
-
Relabeling: Allow the same labeler to relabel an example after a break or time gap, encouraging consistency even within individual labelers.
-
Discussion and Agreement: When disagreements occur, gather the responsible labelers (e.g., machine label engineer, subject matter expert, dedicated labelers) to discuss and establish a more consistent definition for the labels. Document this agreement to serve as updated labeling instructions.
-
Consider Input Information: If labelers express concerns about insufficient information in the input, consider modifying the input itself. For instance, adjusting lighting conditions in photographs to improve visibility.
-
Iterative Process: After making improvements to the input or labeling instructions, request the team to label more data. If inconsistencies persist, repeat the process of involving multiple labelers, addressing major disagreements, and refining the instructions.
Common outcomes of this process include:
-
Standardizing Definitions: Achieving consensus on label definitions enhances data consistency.
-
Merging Classes: When distinguishing between classes becomes ambiguous, merging them into a single class can simplify the task and improve consistency.
-
Creating New Classes: Introducing a new label or class, such as “borderline” or “unintelligible,” helps capture uncertainty and address ambiguous cases, leading to more consistent labeling.
Considerations for small and large datasets:
-
For small datasets, facilitate discussions among labelers to reach agreement on specific examples.
-
For large datasets, establish consistent definitions with a smaller group and then distribute the labeling instructions to a larger group of labelers.
Avoid relying excessively on voting:
-
While voting can be used as a last resort to address noise and inconsistencies, it is preferable to focus on establishing clear label definitions and reducing noise from individual labelers.
-
Strive to make labeler choices less noisy through consistent instructions rather than relying solely on voting mechanisms.
Improving label quality and the role of human-level performance:
-
Human-level performance is an important concept but can be misused. Understanding the baseline human performance on the task is crucial for assessing and improving label quality.
-
The machine learning community should develop tools and machine learning ops tools that aid in detecting and resolving label inconsistencies, facilitating consistent and high-quality data.
By implementing these strategies, you can enhance label consistency and obtain better data for your machine learning tasks.
Major types of data problem
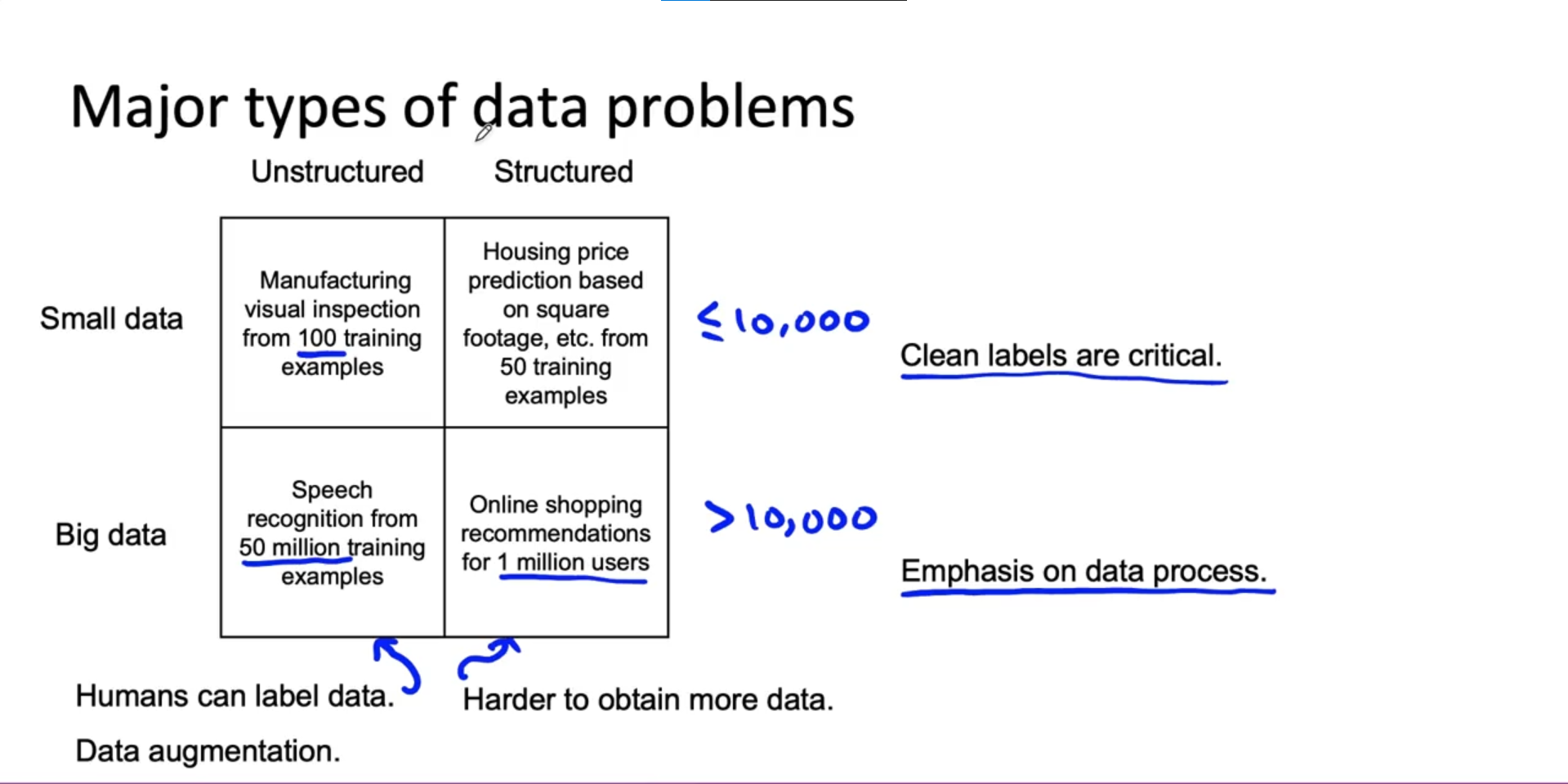 source:
source: - The size of the dataset also affects the approach, with small datasets allowing for manual examination of every example.
- Data augmentation and human labeling are more applicable to unstructured data, while obtaining more data can be challenging for structured data problems.
- Clean labels are crucial for small datasets, while larger datasets require an emphasis on data processes and consistency.