Not to be confused with feature selection.
Tip
Feature selection is simply selecting and excluding given features without changing them. Dimensionality reduction transforms features into a lower dimension space
Why is it a problem?
- More dimensions → more features
- Redundant / irrelevant features
- More noise added than signal
- Hard to interpret and visualize
- Hard to store and process data
- Risk of overfitting our models
- Distances grow more and more alike
- No clear distinction between clustered objects
- Concentration phenomenon for Euclidean distance
Using the same number of data, there will be a point where increasing features will reduces model performances (irrelevant features can have effect to a model depend on the type of the model itself, see: feature selection)
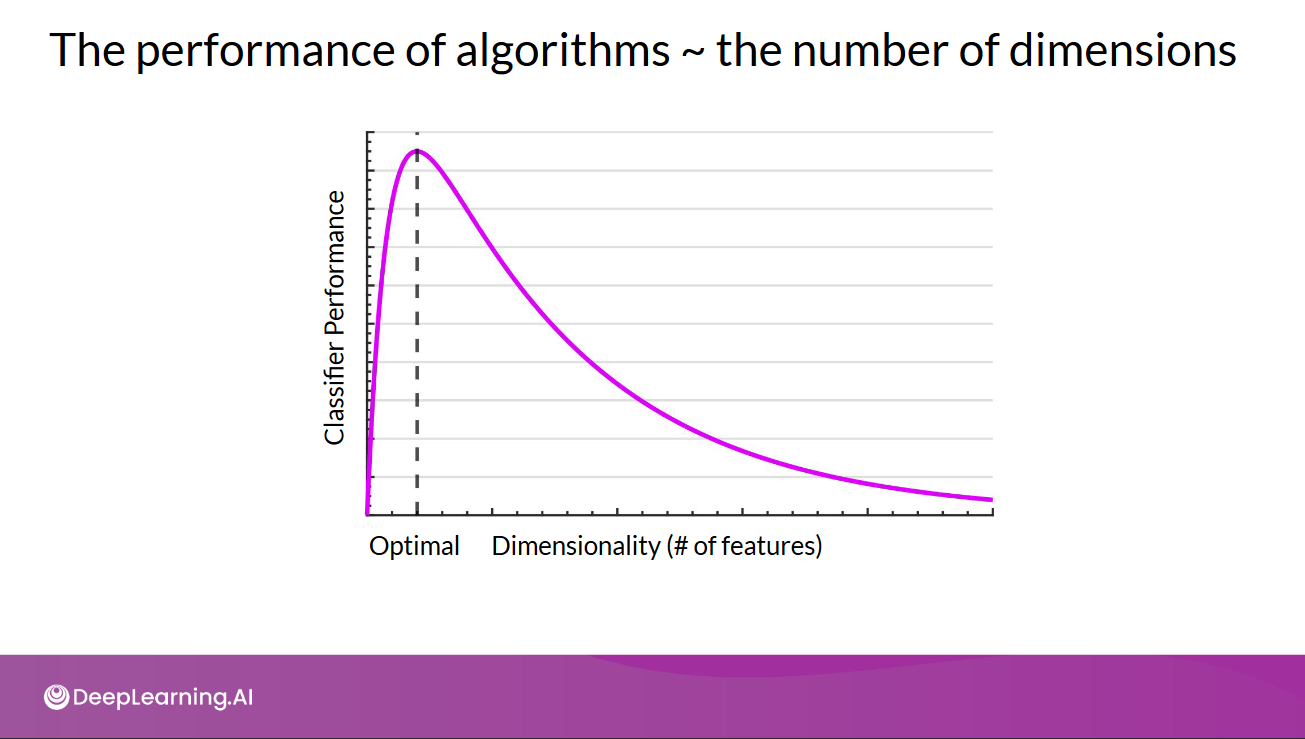 Source: https://community.deeplearning.ai/t/mlep-course-3-lecture-notes/54454
Source: https://community.deeplearning.ai/t/mlep-course-3-lecture-notes/54454
In the distance function:
example: Euclidean distance
$$d_{ij} = \sqrt{\sum_{k=1}^n (x_{ik}-x_{jk})^2}$$
- New dimensions add non-negative terms to the sum
- distances increases with the number of dimensions
- feature space becomes increasingly sparse.
Some Techniques:
some techniques for dimensionality reduction:
- Principal Component Analysis (PCA)
- Linear Discriminant Analysis (LDA)
- Partial Least Squared (PLS)
- Non-Negative Matrix Factorization (NMF)
- Independent Component Analysis (ICA)
- Latent Semantic Indexing/Analysis (LSI and LSA) (SVD)