Distributed training allows for training huge models and speeding up the training process.
Types:
Data parallelism
Dividing data into partitions and copying the complete model to all workers. Each worker operates on a different partition, and model updates are synchronized across workers.
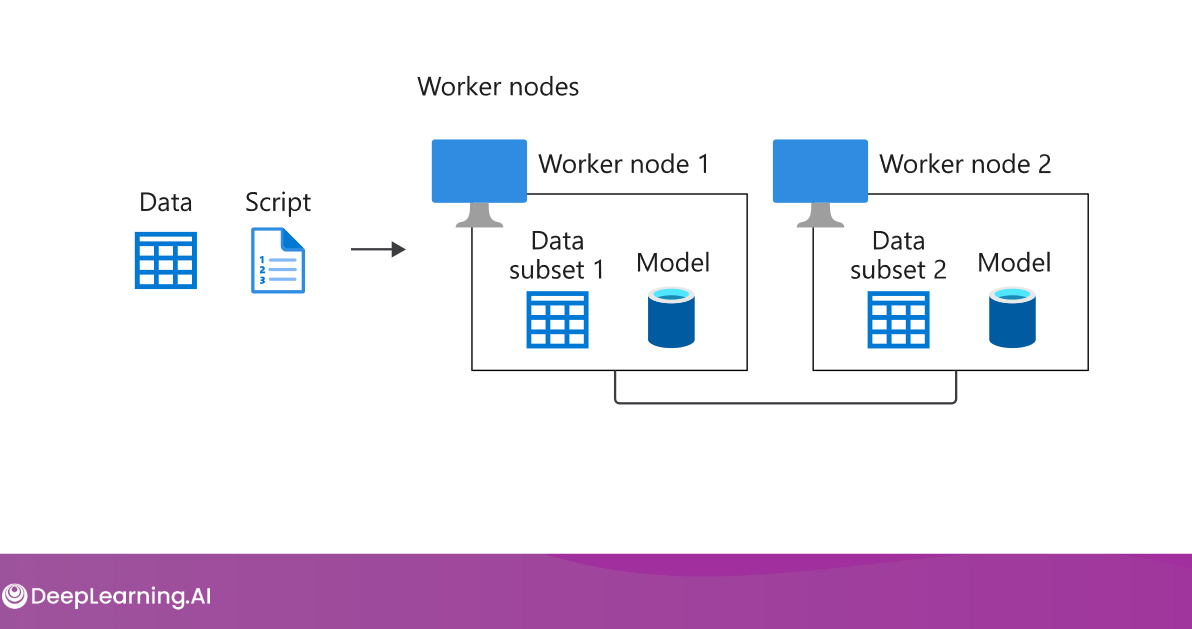 source: https://community.deeplearning.ai/t/mlep-course-3-lecture-notes/
source: https://community.deeplearning.ai/t/mlep-course-3-lecture-notes/
-
Synchronous training: (example: all-reduce architecture) Workers train on it’s current mini-batches of data, apply updates, and wait for updates from other workers before proceeding.
 source: https://youtu.be/S1tN9a4Proc
source: https://youtu.be/S1tN9a4Proc -
Asynchronous training: (parameter-server architecture) Workers independently train on their mini-batches of data and update variables asynchronously. Can be more efficient but may lead to reduced accuracy and slower convergence.
Model parallelism:
Models need to be made distribute-aware.
Segmenting the model into different parts and training concurrently on different workers. Workers synchronize shared parameters during forward and backpropagation steps.
Distribution Strategy:
One Device Strategy:
No Pararelization just for testing.
Mirrored Strategy
This strategy is typically used for training on one machine with multiple GPUs/
- Creates a replica per GPU <> Variables are mirrored
- Weight updating is done using efficient cross-device communication algorithms (all-reduce algorithms)
Parameter-server Strategy
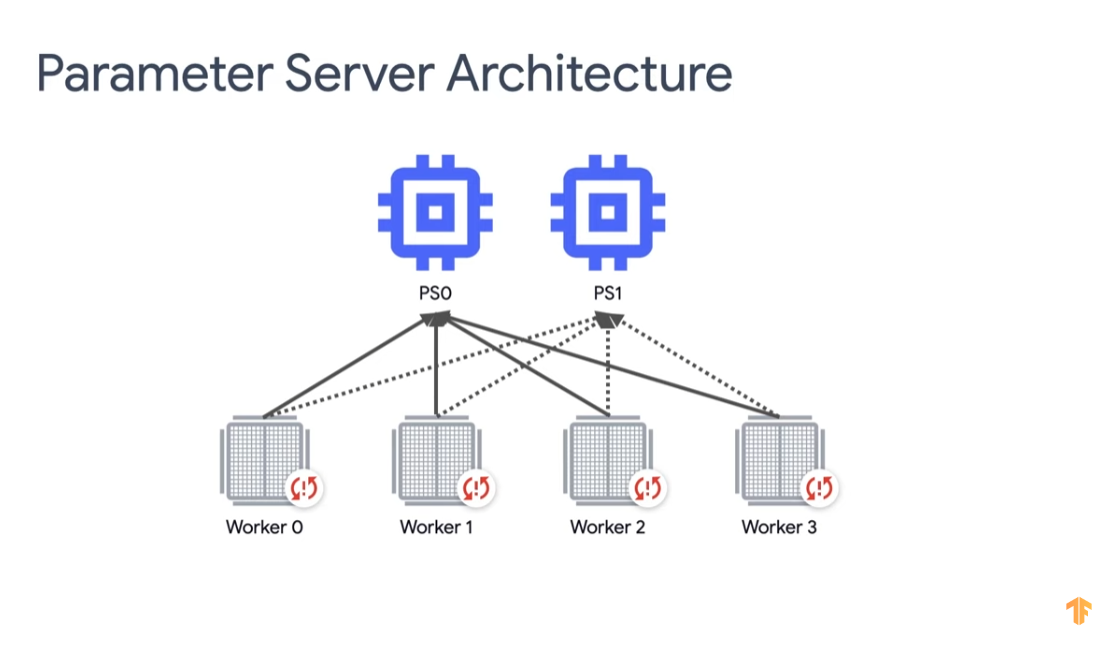 source: https://youtu.be/S1tN9a4Proc
source: https://youtu.be/S1tN9a4Proc