When training a learning algorithm for the first time, it is expected that it won’t work perfectly right away. The key to improving its performance lies in error analysis. By analyzing the errors made by the algorithm, we can determine the most efficient use of our time in improving its performance.
Example: Speech Recognition Error Analysis
To illustrate the error analysis process, let’s consider an example of speech recognition. Here are the steps involved:
-
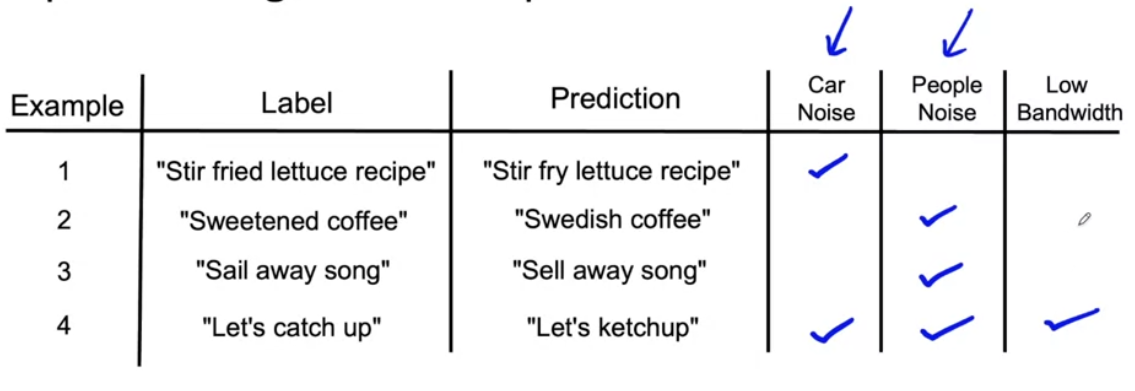
Listen to mislabeled examples: Start by listening to a subset of mislabeled examples from the development set. For each example, compare the ground truth label with the algorithm’s prediction.
-
Identify major data types: Determine the major types of data in the dataset. For speech recognition, this could be categories like car noise and people noise.
-
Create a spreadsheet: Use a spreadsheet program like Google Sheets or Excel to build a spreadsheet with columns for different types of data. Mark each example in the spreadsheet based on its characteristics, such as the presence of car noise or people noise.
-
Iterate and add new tags: As you listen to more examples, you may come up with new tags to describe additional characteristics. Update the spreadsheet accordingly.
-
Analyze error patterns: Look for patterns and analyze the distribution of errors across different tags. This analysis helps identify the categories that contribute to the most errors and require further attention.
 source: https://www.coursera.org/learn/introduction-to-machine-learning-in-production/home/week/2
source: https://www.coursera.org/learn/introduction-to-machine-learning-in-production/home/week/2
Manual vs. MLOps Tools
Traditionally, error analysis has been done manually using spreadsheets or notebooks. However, emerging MLOps tools like LandingLens provide more efficient ways to perform error analysis, especially for computer vision applications.
Prioritizing Improvement Areas
Once error analysis is done, it’s important to prioritize areas for improvement. Consider the following factors:
-
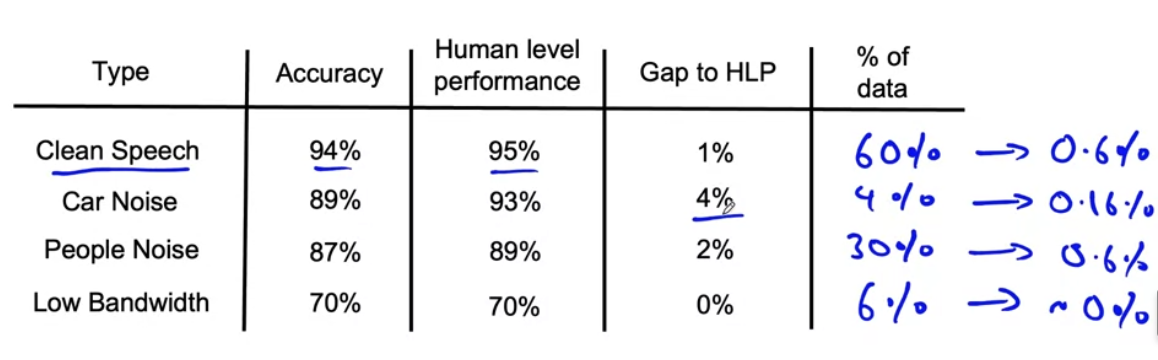
Room for improvement: Evaluate the gap between the algorithm’s performance and human-level performance. Focus on categories with significant room for improvement.
-
Data frequency in that category: Determine the frequency of each category in the dataset. Categories that appear more frequently may be more important to address.
-
Ease of improvement in that category: Assess the feasibility of improving accuracy in each category. Some categories may have clear strategies for improvement, while others may be more challenging.
-
Importance of improvement in that category: Consider the impact of improving performance in each category. Some categories may be more crucial for the overall system’s effectiveness.
for the example above:
 source: https://www.coursera.org/learn/introduction-to-machine-learning-in-production/home/week/2
source: https://www.coursera.org/learn/introduction-to-machine-learning-in-production/home/week/2
Skewed Datasets and Handling Techniques
Skewed datasets, where the ratio of positive to negative examples is imbalanced, require special handling techniques. Consider the following:
-
Confusion matrix: Instead of relying solely on accuracy, construct a confusion matrix to evaluate the performance. The matrix compares actual labels with predictions, allowing a more comprehensive analysis.
-
True positives, true negatives, false positives, false negatives: Fill in the confusion matrix with the counts of examples falling into these four categories to assess the algorithm’s performance.
-
Precision: Precision is the proportion of true positive predictions out of all positive predictions. It helps evaluate the algorithm’s accuracy when it predicts positive instances.
-
Prioritizing improvement: Consider the distribution of examples in the confusion matrix and prioritize improving areas with a significant number of false negatives or false positives.
Conclusion
Error analysis is a crucial step in improving the performance of machine learning algorithms. By carefully analyzing errors, identifying patterns, and prioritizing improvement areas, we can make targeted efforts to enhance the algorithm’s accuracy and overall effectiveness.