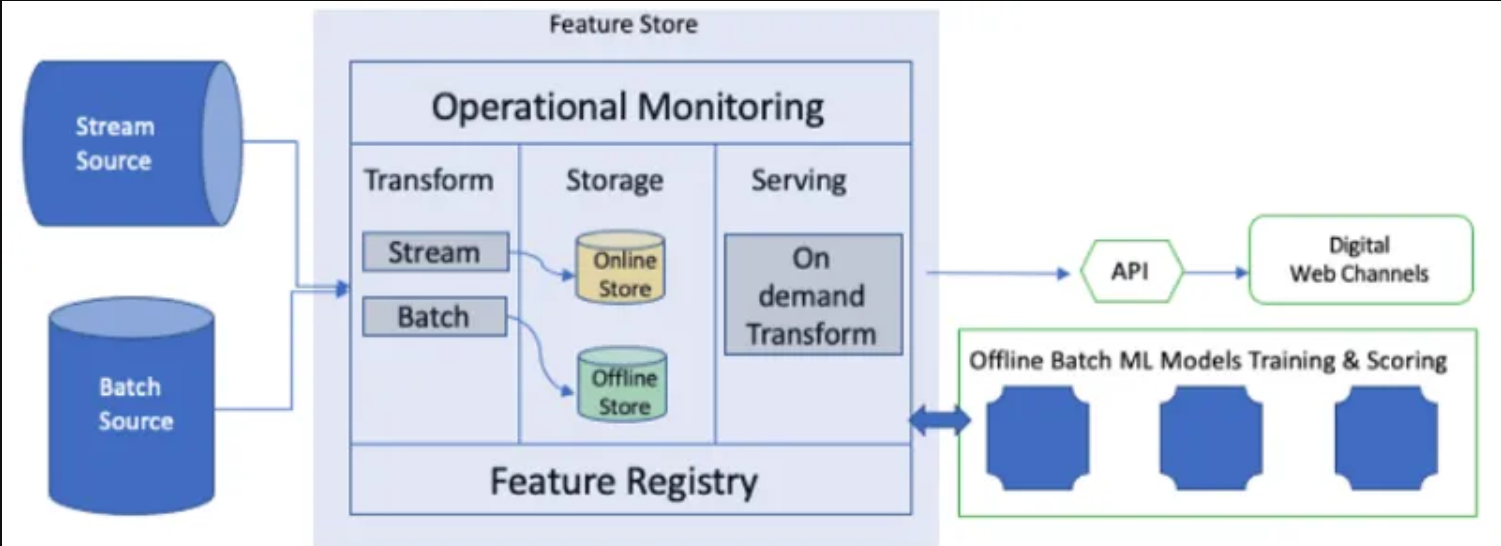
 source: Feature Stores for ML, 2021
source: Feature Stores for ML, 2021
Batch Inference and ETL Pipelines
Batch inference involves using machine learning models to generate predictions for a large number of data points in a batch or scheduled manner, without the need for real-time information.
Batch Inference
Batch inference is used when predictions are not required immediately and can be generated on a recurring schedule, such as daily or weekly. It is useful for scenarios like batch recommendations, where historical data is used to generate predictions without real-time input. Note: it can also be combined with Online Prediction (ML model serving) as part of the feature store.
Tip
Advantages of batch inference include the ability to use complex models without inference time constraints and the absence of the need for prediction caching.
Use Cases of Batch Inference
- E-commerce Site: Generate new product recommendations on a recurring schedule, storing predictions for easy retrieval instead of generating them in real time.
- Sentiment Analysis: Predict sentiment (positive, neutral, negative) based on user reviews, using batch predictions on a recurring schedule to improve services or products over time.
- Demand Forecasting: Estimate product demand on a daily basis for inventory and ordering optimization, leveraging time series models in batch prediction systems.
ETL Pipelines
- Before using data for batch predictions, it needs to be extracted from various sources, transformed, and loaded into an output destination.
- ETL pipelines consist of processes for extracting, transforming, and loading data, typically in a distributed manner for parallel processing.
- Data extraction and transformation can be performed using frameworks like Apache Spark or Google Cloud Dataflow, utilizing the Apache Beam programming paradigm.
- Transformed data is stored in databases or data warehouses before being sent for batch prediction.
Frameworks for Batch Processing and ETL
- In general Data can come from 2 types of sources:
- Batch data available in huge volumes in CSV files, XML files, JSON, APIs, or data lakes like Google Cloud Storage.
- Streaming data from continuously updating sources (or sensors) can be handled by Apache Kafka, Google Cloud Pub/Sub or similar Message Queue tools.
- Apache Spark and Google Cloud Dataflow (based on Apache Beam) are commonly used engines for ETL processing..
- Transformed data can be stored in data warehouses like BigQuery or data lakes before being used for batch prediction or other analytics purposes.