Background
Machine learning is increasingly integrated into mobile, IoT, and embedded applications, with billions of devices already in use.
Reasons for Deploying Models on Device
- Advances in Machine Learning Research: Research enables running inference locally on low-power devices, making it feasible to incorporate machine learning as part of a device’s core functionality.
- Decreasing Hardware Costs: Lower hardware costs allow for affordable devices and higher volume production, making on-device machine learning more accessible.
- Privacy Compliance: On-device machine learning ensures compliance with privacy regulations by keeping user data on the device.
Techniques:
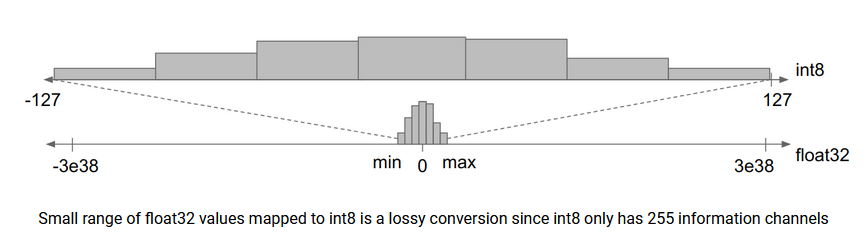
Quantization
 source:
source: Info
- It involves transforming the model into a lower precision representation, such as 8-bit integers.
- Quantized models are smaller in size, faster in computations, and consume less power.
Warning
Introduces information loss due to the reduced number of representable values.
Quantization Aware Training (QAT)
- QAT simulates low-precision computation during the training process to make the model robust to quantization.
- It introduces quantization error as noise and minimizes it through optimization.
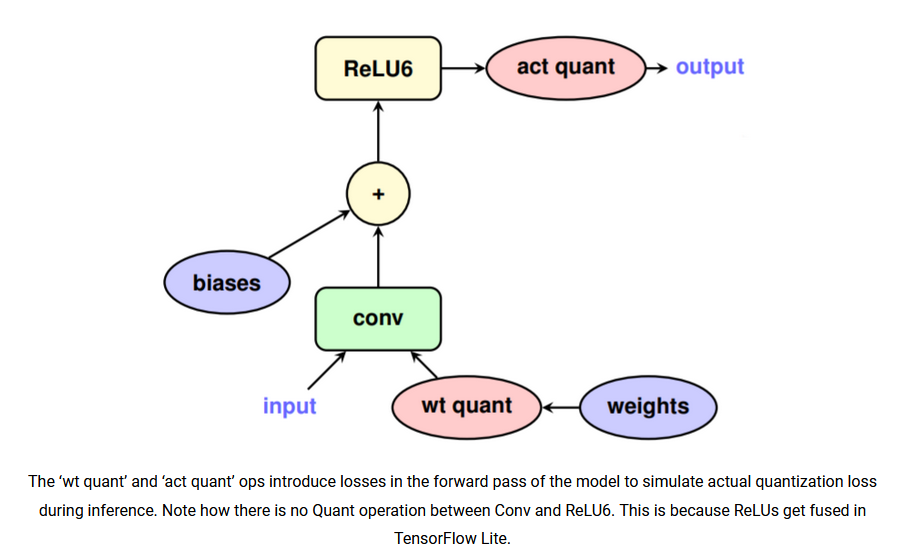
Emulating Low-Precision Computation
- The training graph operates in floating-point precision but emulates low-precision computation.
- Special operations are inserted to convert tensors between floating-point and low-precision values.
Placing Quantization Emulation Operations
Quantization emulation operations need to be placed in the training graph consistently with the quantized graph computation.
 source: https://blog.tensorflow.org/2020/04/quantization-aware-training-with-tensorflow-model-optimization-toolkit.html
source: https://blog.tensorflow.org/2020/04/quantization-aware-training-with-tensorflow-model-optimization-toolkit.html
Example Usage:
import tensorflow_model_optimization as tfmot
model = tf.keras.Sequential([...])
quantized_model = tfmot.quantization.keras.quantize_model(model)
quantized_model.compile(...)
quantized_model.fit(...)
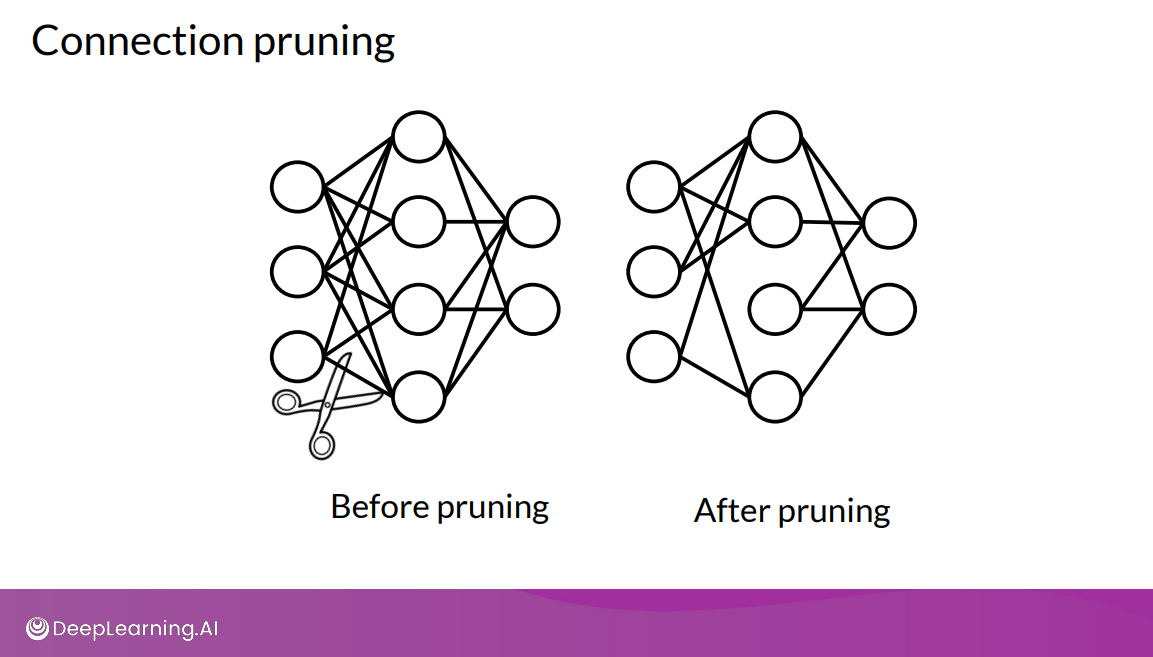
Pruning
Info
Pruning is a method to increase model efficiency by removing unnecessary parts of the model.
It reduces the number of parameters and operations involved in generating predictions.
 source: https://community.deeplearning.ai/t/mlep-course-3-lecture-notes/54454
source: https://community.deeplearning.ai/t/mlep-course-3-lecture-notes/54454
Pruning Techniques
-
Magnitude-based Pruning: This technique removes weights with low magnitudes, assuming they contribute less to the model’s output. The weights are pruned based on their absolute values.
-
Sensitivity-based Pruning: It prunes weights based on their sensitivity to changes in the loss function. The weights with the least sensitivity are pruned.
-
L1-norm Pruning: This method adds an L1-norm regularization term to the loss function, promoting sparsity in weights. It prunes weights with small values.
-
Group-wise Pruning: It prunes entire groups of weights together, instead of individual weights. This approach preserves the structural integrity of the network.