ETL Problem:
Transformations and preprocessing tasks add overhead to the training input pipeline.
Commons ETL:
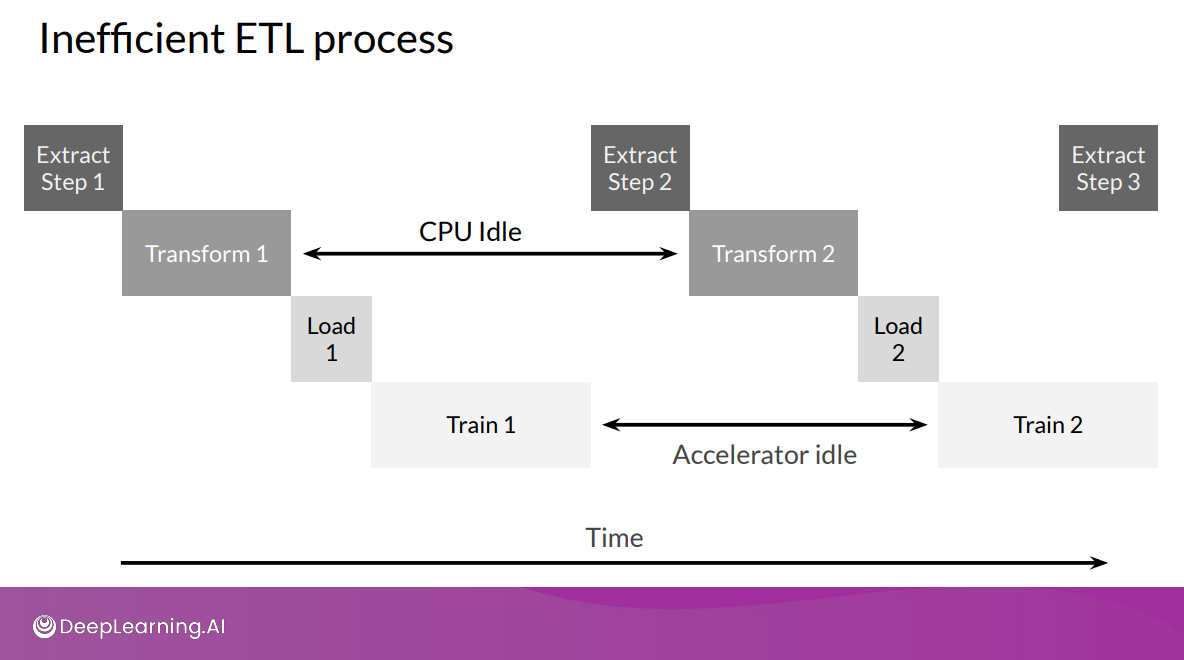 source: https://community.deeplearning.ai/t/mlep-course-3-lecture-notes/54454
source: https://community.deeplearning.ai/t/mlep-course-3-lecture-notes/54454
Problem:
- Input pipelines are needed to supply enough data fast enough to keep accelerators busy.
- Pre-processing tasks and data size can add overhead to the training input pipeline.
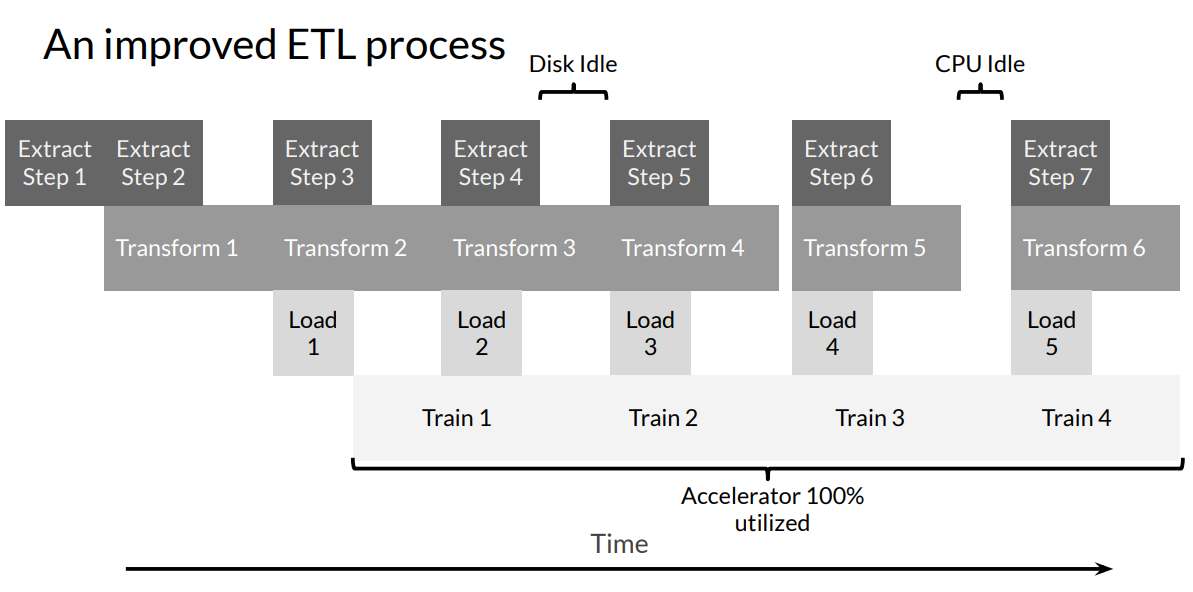
Improved Input Pipeline:
- Parallel processing of data is essential to utilize compute, IO, and network resources effectively.
- Software pipelining can overlap different phases of ETL, resulting in efficient resource utilization.
- Pipelining can overcome CPU bottlenecks by overlapping CPU pre-processing with accelerator model execution.
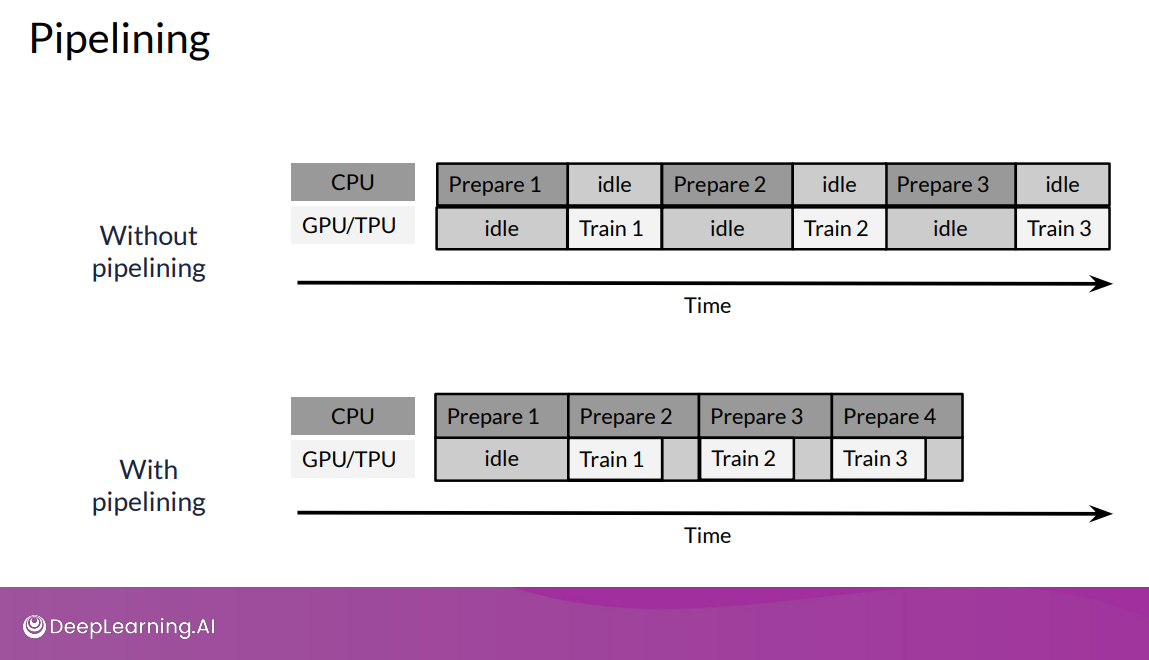
Optimizing Data Pipelines
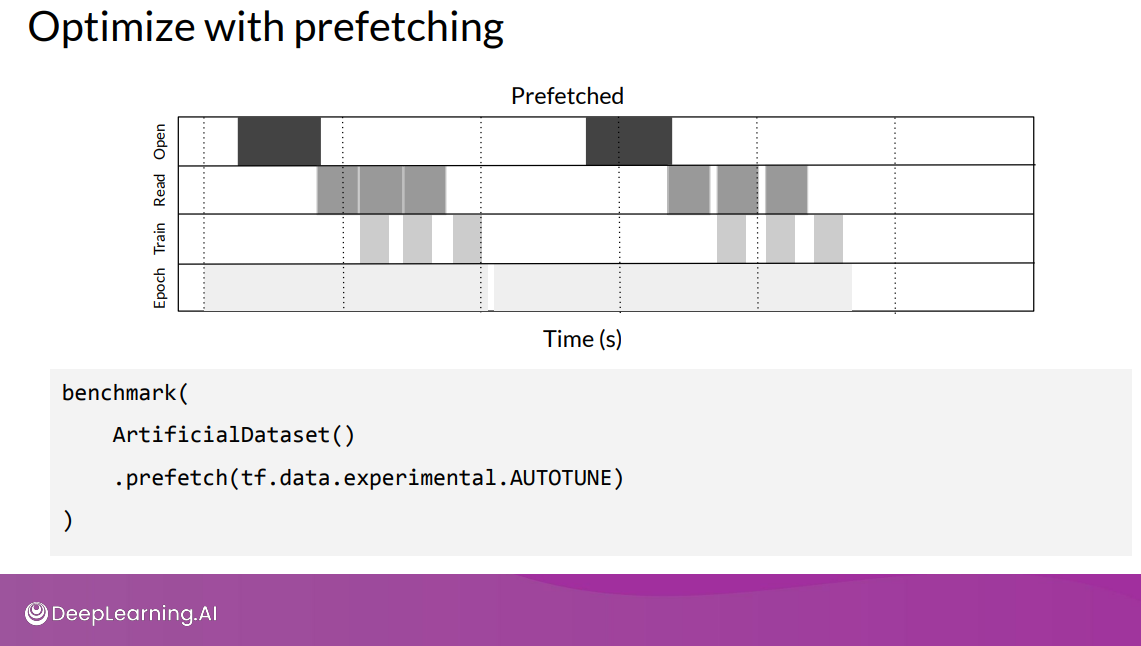
Prefetching
Overlapping the work of producer and consumer to reduce the total time for a step. The number of elements to prefetch should be tuned based on the number of batches consumed per training step.
Parallelize data extraction and transformation
Parallelize Data Extraction
- Reading data from remote storage (e.g., GCS, HDFS) can introduce bottlenecks.
- Time-to-first-byte and read throughput can be significantly slower compared to local storage.
- Pipeline optimization should consider these differences for efficient remote storage access.

Parallelize Data Transformation
Element-wise processing can be parallelized across CPU cores The optimal value for the level of parallelism depends on:
- Size and shape of training data
- Cost of the mapping transformation
- Load the CPU is experiencing currently

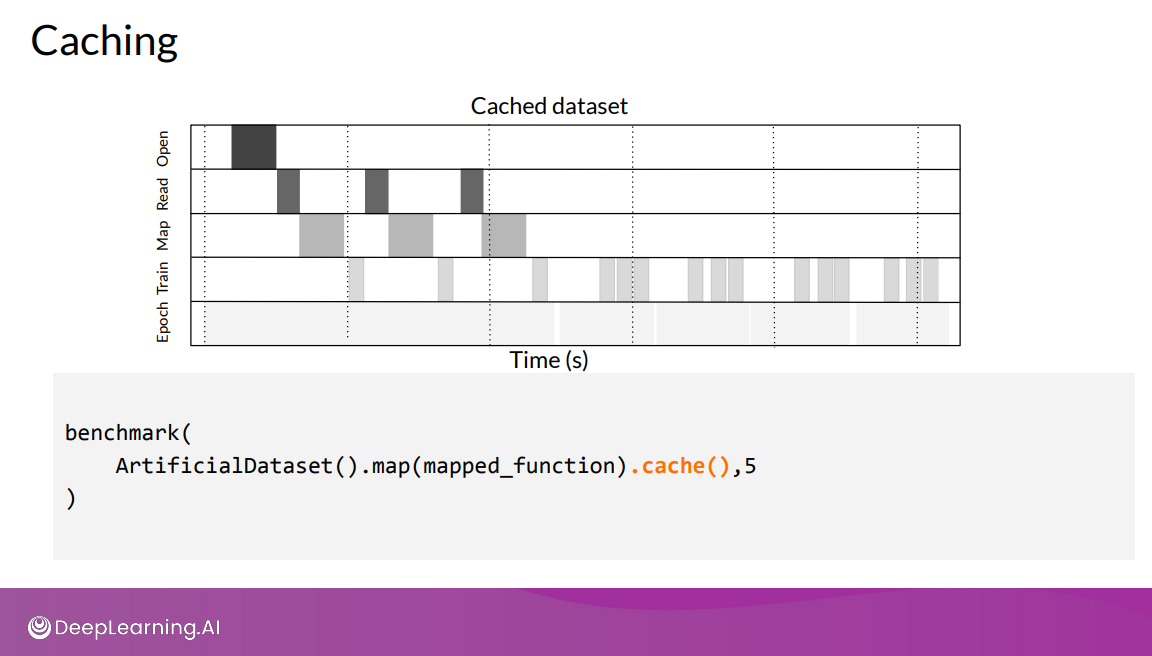
Caching