Vanilla RNN:
$$h_t = F(h_{t-1}, x_t)$$ $$h_t = activation(W_h\ h_{t-1} + W_x\ x_t)$$ $$y_t = W_y \ h_t$$
 image source: https://youtu.be/6niqTuYFZLQ
image source: https://youtu.be/6niqTuYFZLQ
Problem:
- hard to remember long sentences
- Vanishing and Exploding Gradient problem
LSTM:
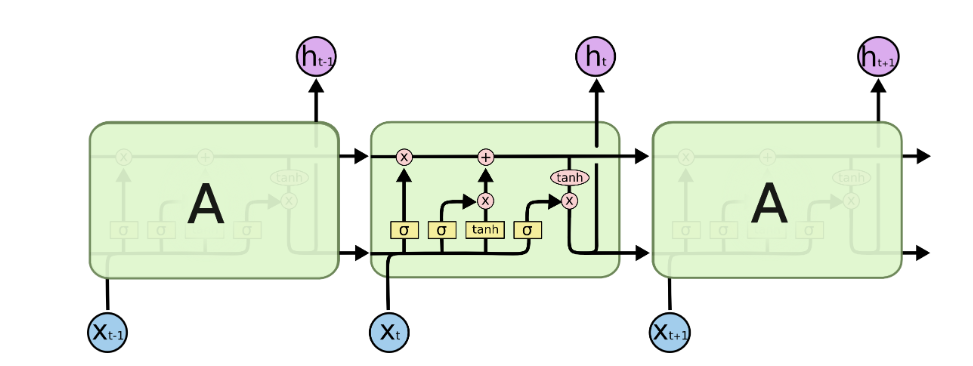 image from https://colah.github.io/posts/2015-08-Understanding-LSTMs/
image from https://colah.github.io/posts/2015-08-Understanding-LSTMs/
Forget gate:
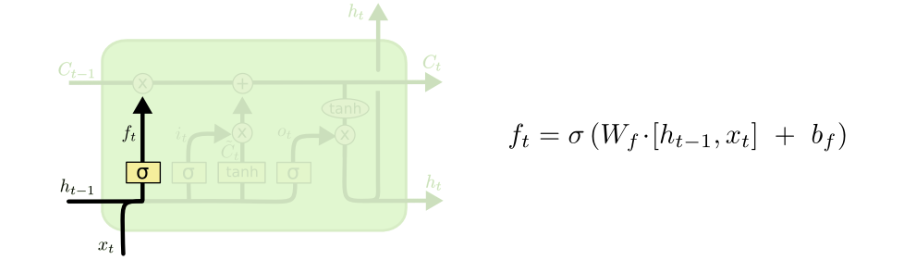
since i’s using sigmoid function the output would be 0-1 (decide how much we should forget the long term memory, if 0 forget)
Input gate:
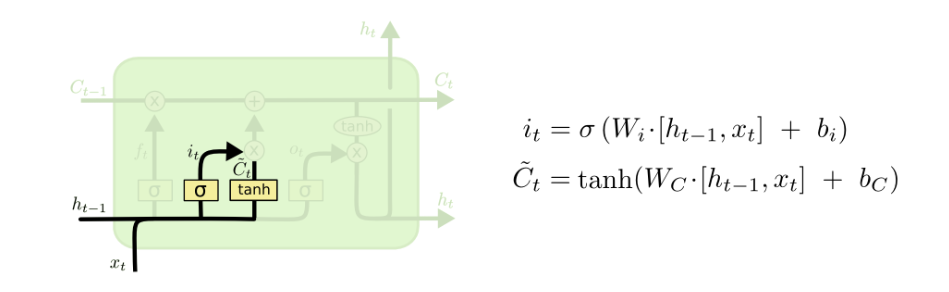
tanh: used to update $C_{t-1}$ from $C_t$ sigmoid: used to decide on how much we should update $C_{t-1}$ from $C_t$
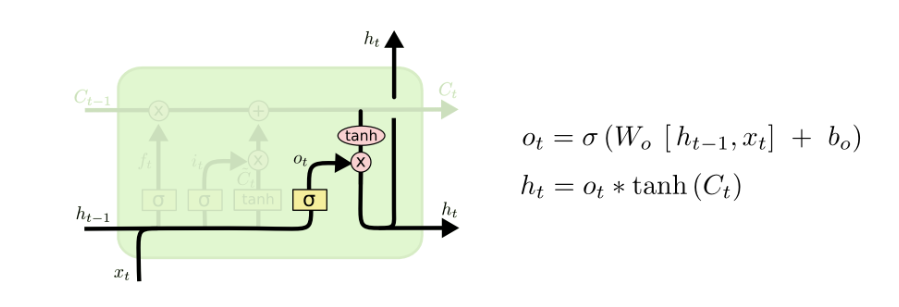
Output gate: