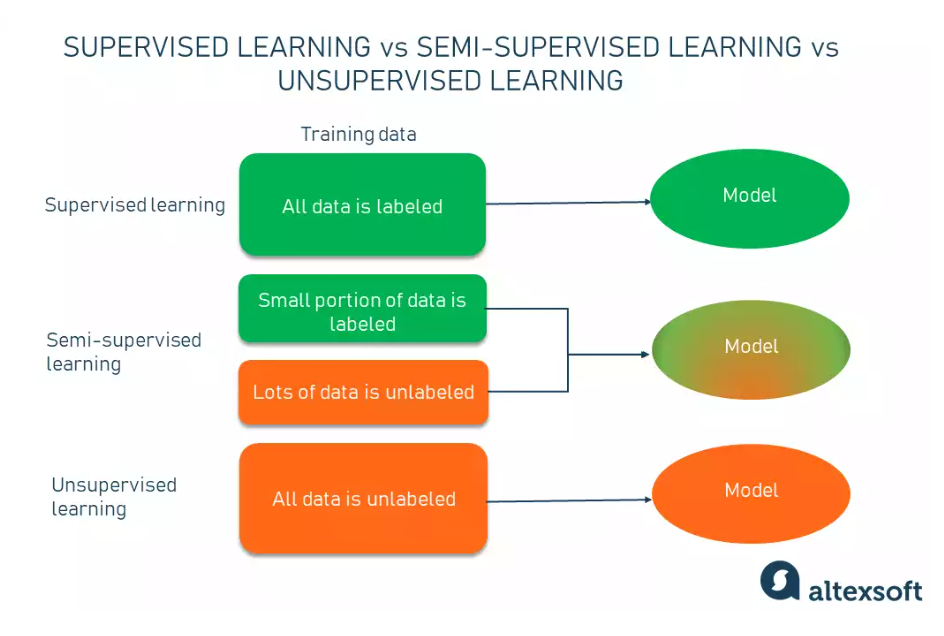
Semi-supervised learning is a technique that combines a small labeled dataset with a large unlabeled dataset to improve model performance. The process involves inferring labels for the unlabeled data based on how labeled classes are structured within the feature space.
Semi-supervised learning assumes that different label classes exhibit clustering or recognizable structure.
 source: https://www.altexsoft.com/blog/semi-supervised-learning/
source: https://www.altexsoft.com/blog/semi-supervised-learning/
Key Principle
Instead of adding tags to the entire dataset, you go through and hand-label just a small part of the data and use it to train a model, which then is applied to the ocean of unlabeled data.
Techniques:
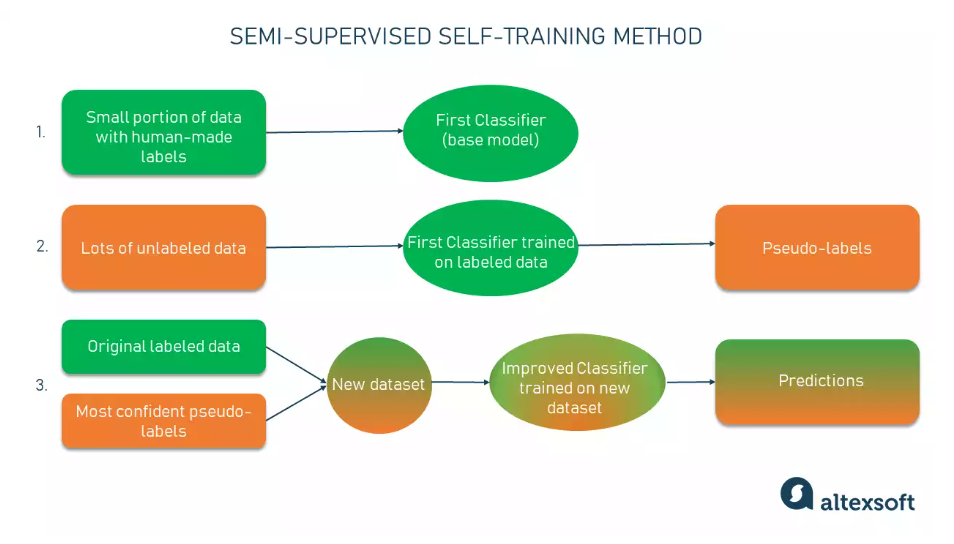
Self-Training
 source: https://www.altexsoft.com/blog/semi-supervised-learning/
source: https://www.altexsoft.com/blog/semi-supervised-learning/
- Train a base model using a small amount of labeled data through supervised methods.
- Apply pseudo-labeling, where the partially trained model predicts labels for the unlabeled data.
- Select the most confident predictions above a certain threshold and add them to the labeled dataset.
- Create a new combined input from the labeled and pseudo-labeled data to train an improved model.
- Iterate this process multiple times, adding more pseudo-labels at each iteration to improve model performance.
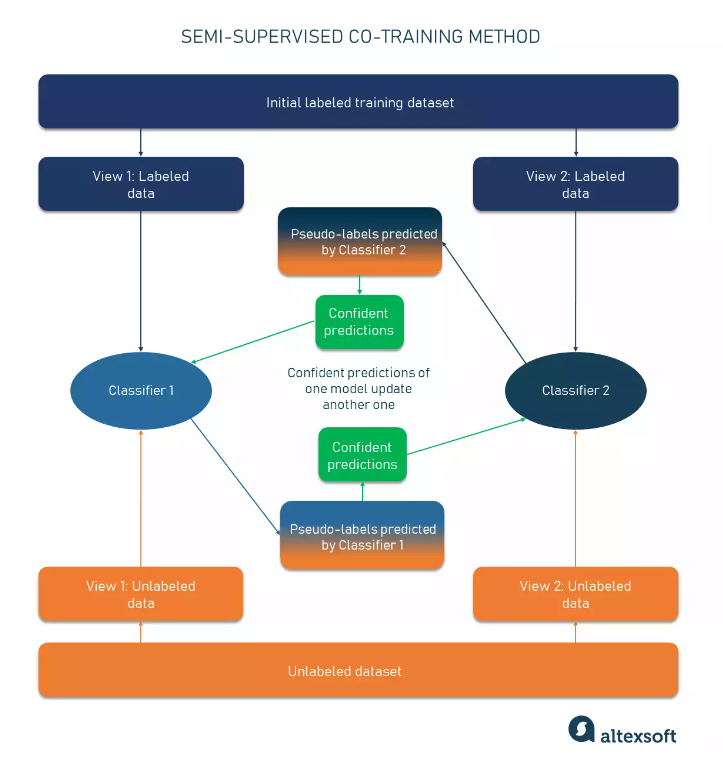
Co-Training
 source: https://www.altexsoft.com/blog/semi-supervised-learning/
source: https://www.altexsoft.com/blog/semi-supervised-learning/
- Train separate classifiers for each view using a small amount of labeled data.
- Add the larger pool of unlabeled data and generate pseudo-labels.
- Co-train the classifiers using the pseudo-labeled data with the highest confidence level.
- Update each classifier using confident pseudo-labels assigned by the other classifier.
- Combine the predictions from the two updated classifiers to obtain the final classification result.
- Iterate this process to create an additional labeled dataset from the unlabeled data.
Label Propagation
Graph-based label propagation
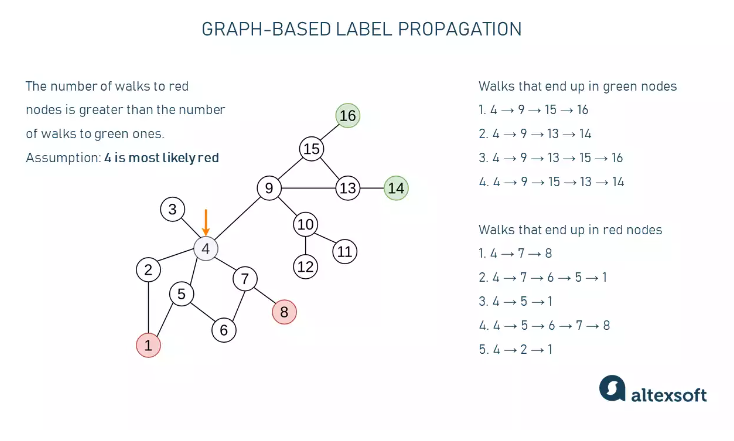
- Represent the data as a graph, with most points being unlabeled and a few carrying labeled points.
- Propagate the colored labels throughout the network using paths connecting each data point.
- Count the number of paths leading to different colored nodes to determine the label for each point.
- Repeat this process for every point on the graph.
Graph-based label propagation is commonly used in personalization and recommender systems to predict customer interests based on connections between users.